The Power of Data Visualization 📊
Turning numbers into insights through visual communication
Complex Multi-Panel Analysis
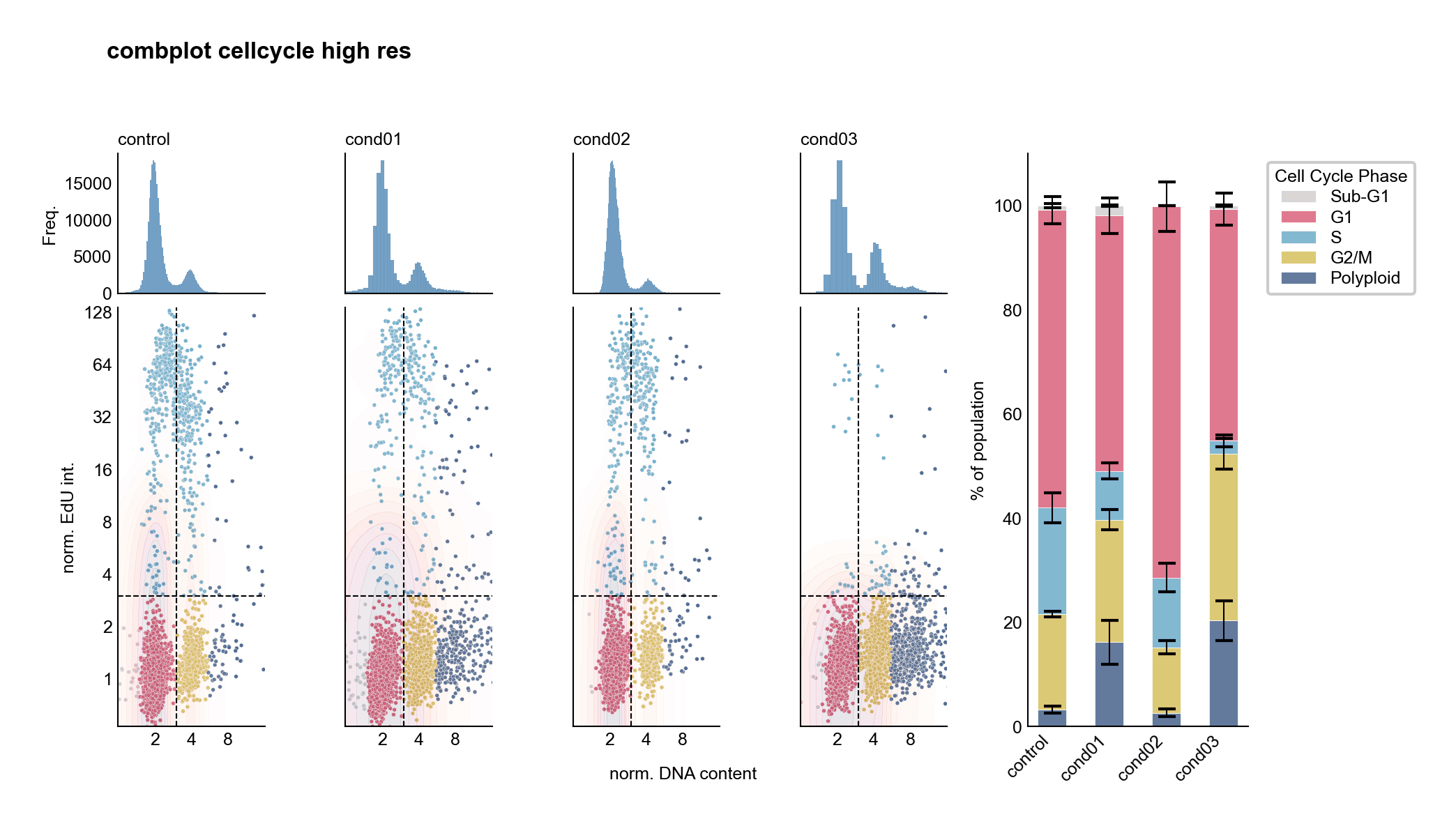
Cell cycle analysis: Histograms, scatter plots, and stacked bars reveal different aspects of the data
Comparative Stacked Bar Charts
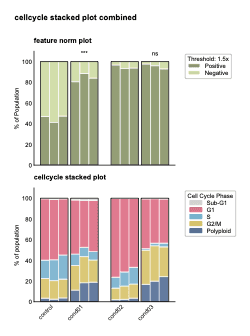
Stacked bars show proportions and statistical significance across experimental conditions
🎯 Why Data Visualization is Essential
See Patterns Instantly
Your brain processes visual information 60,000× faster than text. Spot trends, outliers, and relationships at a glance.
Reveal Hidden Insights
Distributions, correlations, and anomalies that are invisible in tables become obvious in plots.
Compare Across Groups
Quickly compare multiple conditions, time points, or experimental groups side-by-side.
Guide Statistical Analysis
Visualizations help you choose the right statistical tests by revealing data distributions and relationships.
Communicate Results
Figures are the universal language of science. A good plot tells your story better than paragraphs of text.
Quality Control
Catch data errors, batch effects, and technical artifacts before they ruin your analysis.
🛠️ Your Visualization Toolkit
Matplotlib
Python's foundational plotting library. Complete control over every element.
Seaborn
Beautiful statistical plots with minimal code. Built on matplotlib.
Pandas Plotting
Quick exploratory plots directly from DataFrames.
💡 Visualization First, Statistics Second
Always visualize your data before running statistical tests.A single plot can reveal what hours of statistical analysis might miss. In biology, understanding your data visually is not optional—it's essential for drawing correct conclusions and telling compelling scientific stories.
Essential Plot Types 📊
Choosing the right visualization for your data

Scatter Plot
Relationship between two variables
When to use:
- • Two continuous variables
- • Looking for correlations
- • Identifying outliers
- • Each point is an observation
Biological Examples:
- • Gene A vs Gene B expression
- • Cell size vs proliferation rate
- • Drug dose vs response
fig, ax = plt.subplots()ax.scatter(df['BRCA1'], df['TP53'])ax.set_xlabel('BRCA1 Expression')ax.set_ylabel('TP53 Expression')
Line Plot
Trends over time or ordered sequence
When to use:
- • Time series data
- • Showing trends/changes
- • Connecting ordered points
- • Multiple groups over time
Biological Examples:
- • Cell growth over time
- • Gene expression during differentiation
- • Drug concentration in blood
fig, ax = plt.subplots()ax.plot(time_points, cell_count)ax.set_xlabel('Time (hours)')ax.set_ylabel('Cell Count')
Bar Chart
Comparing categories or groups
When to use:
- • Categorical data
- • Comparing groups
- • Discrete counts
- • Clear group differences
Biological Examples:
- • Cell counts per tissue type
- • Mean expression by cancer lineage
- • Number of mutations per gene
fig, ax = plt.subplots()ax.bar(categories, values)ax.set_xlabel('Cancer Lineage')ax.set_ylabel('Mean Expression')
Histogram
Distribution of continuous data
When to use:
- • One continuous variable
- • See data distribution shape
- • Check for normality
- • Identify skewness/outliers
Biological Examples:
- • Distribution of gene expression
- • Cell size distribution
- • Mutation frequency across genes
fig, ax = plt.subplots()ax.hist(df['BRCA1'], bins=30)ax.set_xlabel('BRCA1 Expression')ax.set_ylabel('Frequency')
Box Plot
Compare distributions across groups
When to use:
- • Compare multiple groups
- • Show median, quartiles, outliers
- • Continuous data across categories
- • Compact distribution summary
Biological Examples:
- • Gene expression by cancer type
- • Cell viability across treatments
- • Protein levels in different tissues
fig, ax = plt.subplots()ax.boxplot([group1, group2, group3])ax.set_xticklabels(['Control', 'Drug A', 'Drug B'])ax.set_ylabel('Expression Level')
Violin Plot
Box plot + full distribution shape
When to use:
- • Like box plot but more detail
- • Show full distribution shape
- • Reveal bimodal distributions
- • Multiple groups comparison
Biological Examples:
- • Cell cycle phase distributions
- • Expression patterns across lineages
- • Multimodal phenotype data
import seaborn as snsfig, ax = plt.subplots()sns.violinplot(data=df, x='lineage', y='BRCA1', ax=ax)🎯 Quick Decision Guide
One Variable:
Histogram (distribution) or Bar chart (categories)
Two Variables:
Scatter (correlation) or Line (trend over time)
Groups Comparison:
Box plot or Violin plot (show distributions)
Visual Aesthetics 🎨
Using visual properties to encode data dimensions
What are Aesthetics?
Aesthetics are visual properties (position, color, size, shape) that we map to data variables to communicate information. Each aesthetic channel encodes a different dimension of your data.

Position (x, y)
Most powerful aesthetic - use for key variables
Characteristics:
- • Most accurate perception
- • Two independent channels (x and y)
- • Best for continuous data
- • Primary way to show relationships
Biological Example:
Gene expression scatter plot
fig, ax = plt.subplots()ax.scatter(df['BRCA1'], df['TP53'])# x-position = BRCA1 expression# y-position = TP53 expression
Color
Add categorical or continuous dimensions
Two Types:
- • Categorical: Distinct hues for groups
- • Continuous: Color gradient for values
- • Draws attention effectively
- • 3-7 colors max for categories
Biological Example:
Color by cancer lineage
fig, ax = plt.subplots()for lineage in df['lineage'].unique(): subset = df[df['lineage'] == lineage] ax.scatter(subset['x'], subset['y'], label=lineage)ax.legend()
Size
Encode magnitude or importance
Characteristics:
- • Best for continuous data
- • Shows relative magnitude
- • Can add a 3rd dimension
- • Avoid extreme size differences
Biological Example:
Bubble plot: size = cell count
fig, ax = plt.subplots()ax.scatter(df['gene_A'], df['gene_B'], s=df['cell_count']/10, alpha=0.6)# size encodes cell count
Shape
Distinguish categories (limit to 3-5)
Characteristics:
- • Only for categorical data
- • Harder to distinguish than color
- • Maximum 5-6 different shapes
- • Combine with color for clarity
Biological Example:
Different markers for treatment groups
markers = {'Control': 'o', 'Drug_A': 's', 'Drug_B': '^'}for treatment, marker in markers.items(): subset = df[df['treatment'] == treatment] ax.scatter(subset['x'], subset['y'], marker=marker, label=treatment)
Line Width
Emphasize importance or magnitude
Characteristics:
- • Shows importance/weight
- • Can encode continuous data
- • Use subtle variations
- • Effective for network graphs
Biological Example:
Line thickness by confidence
fig, ax = plt.subplots()ax.plot(time, group_A, linewidth=3, label='High confidence')ax.plot(time, group_B, linewidth=1, label='Low confidence')
Line Type
Distinguish categories in line plots
Characteristics:
- • Solid, dashed, dotted, dash-dot
- • For categorical groups
- • Maximum 3-4 different types
- • Combine with color
Biological Example:
Different line styles for conditions
fig, ax = plt.subplots()ax.plot(time, control, linestyle='-', label='Control')ax.plot(time, treated, linestyle='--', label='Treated')ax.plot(time, predicted, linestyle=':', label='Predicted')🎯 Aesthetic Effectiveness Hierarchy
Most Effective:
Position (x, y) - Use for your most important variables
Moderately Effective:
Color, Size - Good for adding dimensions
Less Effective:
Shape, Line type - Use sparingly, combine with color
Further Reading 📚
Excellent resources to deepen your data visualization skills

Fundamentals of Data Visualization
by Claus O. Wilke
Why read this:
- • Comprehensive guide to effective visualization
- • Principles of visual perception
- • Choosing the right plot type
- • Color theory and design principles
- • Available free online!

Data Visualisation: A Handbook for Data Driven Design
by Andy Kirk
Why read this:
- • Practical, hands-on approach
- • Design workflow and process
- • Real-world examples and case studies
- • Modern tools and techniques
- • Publication-ready visualizations
📖 More Learning Resources
Online Galleries
- • Python Graph Gallery
- • Seaborn Example Gallery
- • Matplotlib Examples
Interactive Tutorials
- • DataCamp courses
- • Kaggle Learn
- • Real Python tutorials
Scientific Examples
- • Nature Methods guides
- • Ten Simple Rules papers
- • Scientific plotting guides